
How I Learned to Stop Worrying and Love Juggling C++ Atomics
As most C++ programmers are aware, courtesy of Herb Sutter, programming lock-free data structures is akin to juggling razor blades. Reasoning about concurrent programs is already complex enough but modern CPU memory models are so complicated that they manage to make it even harder. The prevailing suggestion you often come across is to steer clear of lock-free programming entirely.
Yet, there exists a shadowy realm where such recklessness is not just an option; it's a dire necessity. It's a call to arms, a siren's song, and it beckons to the restless souls of software engineers driven by the insatiable thirst for high performance.
In this article, I share the adventures of exploring methods for formally verifying lock-free C++ code. To showcase three different approaches, I delve into the implementation of a lock-free triple buffer data structure.
What’s a triple-buffer?
A triple buffer is like a double buffer, but triple!
What’s a double buffer then?
A double buffer is used in cases when you modify the state while another process needs to access it. While it’s okay for the consumer process to see stale data from previous modifications, it is not okay to see a noncomplete modification in progress. This data structure is very common in computer graphics: usually, you have 2 buffers - “front buffer” and “back buffer”.
- The front buffer is the portion of memory that directly corresponds to the pixels on the screen. The front buffer is what the user sees on the screen at any given moment.
- The back buffer is used to create and store the next frame or image that you want to display. Rendering is done in the back buffer, away from the user’s view. Once the back buffer is complete and ready to be displayed, it can be swapped with the front buffer.
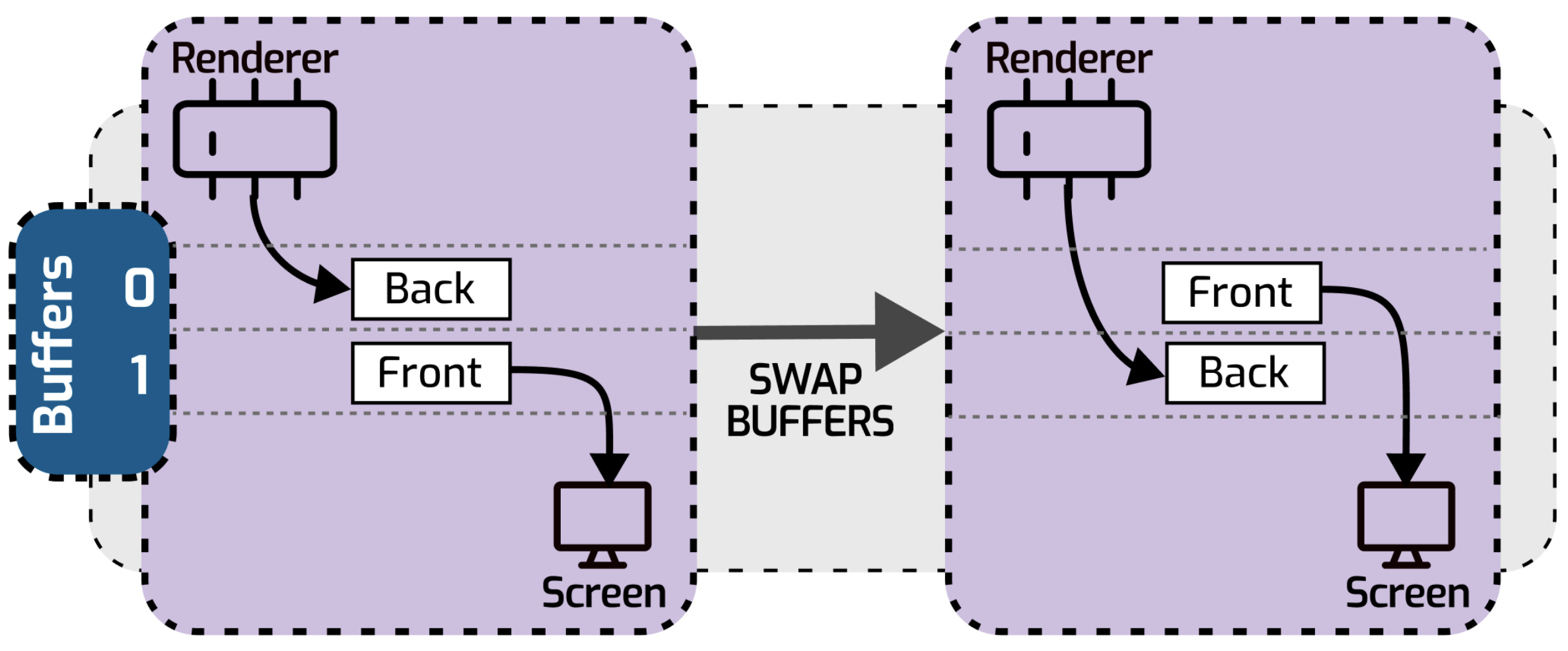 The double buffering technique works by updating the back buffer with the new image or frame, and when it’s ready to be displayed, the roles of the front and back buffers are switched. It ensures that the user never sees a partially drawn or flickering image because the new frame is presented only when it’s fully drawn in the back buffer. Those swaps typically happen 60 times per second.
The double buffering technique works by updating the back buffer with the new image or frame, and when it’s ready to be displayed, the roles of the front and back buffers are switched. It ensures that the user never sees a partially drawn or flickering image because the new frame is presented only when it’s fully drawn in the back buffer. Those swaps typically happen 60 times per second.
However, double buffers are useful in other real-time systems beyond graphics programming and game development.
Add one more buffer
The problem with double buffering is that you cannot swap buffers while reading or writing is in progress so that requires a wait until either read or write is finished. That is a common problem in video game graphics where the frame rate gets capped by Vsync.
To avoid the wait we can introduce the 3rd buffer hence “triple buffer”!
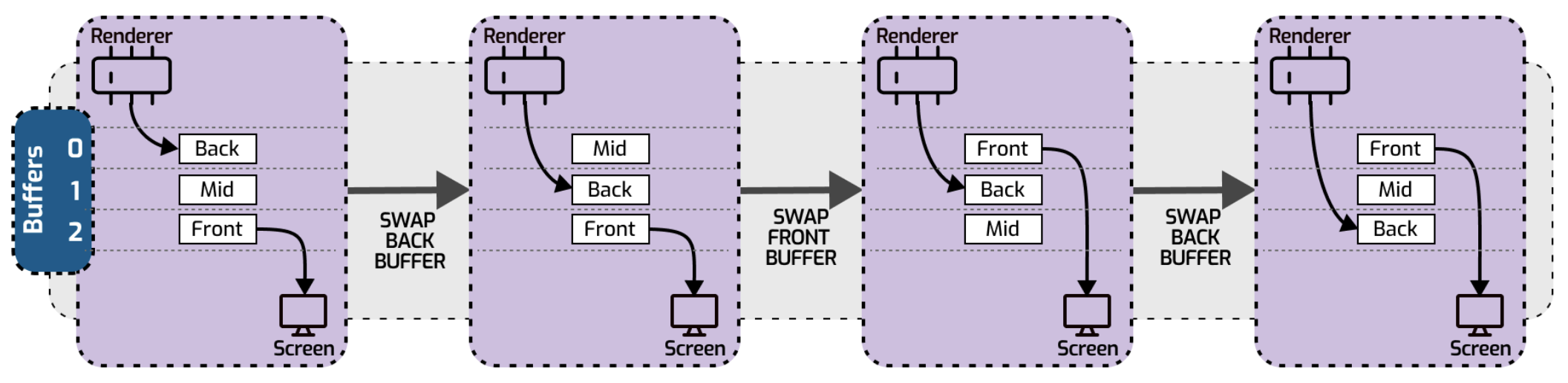 We can then use one buffer for the producer to prepare results, the second buffer to store the latest produced results, and the third buffer for the consumer. Both producer and consumer can always swap buffers without the need for cumbersome synchronization. It’s a nice method for efficiently moving data from a single producer to a single consumer, free from the hurdles of locking or busy wait. Going back to the computer graphics example - a triple buffering technique is usually used to improve game FPS.
We can then use one buffer for the producer to prepare results, the second buffer to store the latest produced results, and the third buffer for the consumer. Both producer and consumer can always swap buffers without the need for cumbersome synchronization. It’s a nice method for efficiently moving data from a single producer to a single consumer, free from the hurdles of locking or busy wait. Going back to the computer graphics example - a triple buffering technique is usually used to improve game FPS.
Implementation
I will intentionally implement a triple buffer with a data race bug. We will try and see if we can find this bug via automated tooling. The corrected code is in this repo.
// A very buggy single producer/single consumer triple buffer implementation.
class Trio {
public:
// Consumer side. Consumer calls Read() to get a buffer with either
// stale data or the latest committed data.
T& Read() {
// First, check if there's newly committed data in the middle buffer.
// Return stale data otherwise.
bool isDirty = dirty_.load(std::memory_order_relaxed);
if (isDirty) {
// Swap the front buffer with the middle buffer and reset the dirty flag
front_buffer_ = middle_buffer_.exchange(front_buffer_, std::memory_order_acq_rel);
dirty_.store(false, std::memory_order_relaxed);
}
return *front_buffer_;
}
// Producer side. Get the current back buffer to write to it.
T& Write() {
return *back_buffer_;
}
// Producer side. Commit written data and swap the back buffer and
// the middle buffer.
void Commit() {
// Swap buffer pointers and mark the middle buffer dirty so that the consumer
// knows that we have new committed data.
back_buffer_ = middle_buffer_.exchange(back_buffer_, std::memory_order_acq_rel);
dirty_.store(true, std::memory_order_relaxed);
}
private:
// Prevent implicit data sharing between threads
static constexpr size_t kNoSharing = 64;
struct alignas(kNoSharing) Buffer {
T data{};
};
Buffer buffers_[3];
// Dirty flag. Indicates that there's new data in the middle buffer.
std::atomic<bool> dirty_{false};
std::atomic<T*> middle_buffer_{&buffers_[1].data};
alignas(kNoSharing)
T* front_buffer_{&buffers_[0].data}; // only consumer accesses this
alignas(kNoSharing)
T* back_buffer_{&buffers_[2].data}; // only producer accesses this
};
We have 3 “buffers” that can really be any user-provided type. The consumer reads either stale data or (if available) newly committed data. To convey to the consumer that new data is ready for reading from the middle buffer, we add a boolean “dirty” flag. Once the data modifications are finished, the user is expected to call Commit(), and the consumer swaps the back buffer with the middle buffer and marks the data dirty. During the subsequent read, the consumer will check the dirty flag and swap the front buffer and the middle buffer if needed. That sounds okay and even if we run a simple example; it looks like it works fine. However, this implementation does have a bug.
Verification
In my quest, I stumbled upon a handful of tools that promise automated verification of concurrent algorithms. Let’s go over a few of them that seemed most promising.
Relacy
Relacy race detector is a C++ library for writing unit tests for multithreaded code. You instrument your concurrent code with special hooks and then Relacy is able to emulate multiple possible orders of execution of concurrent code. The emulation itself is single-threaded. Relacy is using coroutines to break inside your code and reorder data accesses. It is able to emulate C++0x memory model with regards to memory fences, check for data races, deadlocks, live locks, and many more. Though my initial reservations had doubts about a decade-old project with its latest commit dating back to 2019, I was pleasantly astounded. Integrating Relacy and seamlessly compiling it with the latest Clang, both on Mac and Linux, turned out to be remarkably smooth. The instrumented buggy triple buffer is the following:
// A very buggy single producer/single consumer triple buffer
// instrumented with relacy.
template<typename T>
class Trio {
public:
T& Read() {
bool isDirty = dirty_($).load(rl::mo_relaxed);
if (isDirty) {
front_buffer_ = middle_buffer_($).exchange(front_buffer_, rl::mo_acq_rel);
dirty_($).store(false, rl::mo_relaxed);
}
return *front_buffer_;
}
T& Write() {
return *back_buffer_;
}
void Commit() {
back_buffer_ = middle_buffer_($).exchange(back_buffer_, rl::mo_acq_rel);
dirty_($).store(true, rl::mo_relaxed);
}
private:
static constexpr size_t kNoSharing = 64;
// avoid false-sharing, align buffers to cache-line size
struct alignas(kNoSharing) Buffer {
T data{0};
};
Buffer buffers_[3];
rl::atomic<bool> dirty_{false};
rl::atomic<T*> middle_buffer_{&buffers_[1].data};
alignas(kNoSharing)
T* front_buffer_{&buffers_[0].data};
alignas(kNoSharing)
T* back_buffer_{&buffers_[2].data};
};
In the real world, you would want to be able to switch from the production version to the instrumented version via some macro or templated traits but here for the sake of clarity, I will keep the instrumented version separately. As you can see differences with the original code are minimal: Relacy uses variable $ to pass internal state around, and a few std thread/atomic calls need to be changed to rl:: namespace.
We can now unit-test our triple-buffer and let Relacy emulate as many scenarios as we can. For the unit test I will check those 2 simple conditions:
- Consumer sees all modifications that Producer did in the same order as they were made. It’s okay to lose some intermediate states if they were overwritten before the consumer read them.
- Once the producer stops - the consumer is able to see the latest value that was written. In addition, Relacy itself will check code for data races, deadlocks, and livelocks and report any findings. Here’s what it looks like:
#include <relacy/relacy.hpp>
// Will create 2 "threads":
// One for consumer, one for producer
static constexpr size_t kThreads = 2;
// Each buffer is just a single integer.
// Testing for:
// - Order of updates is the same for producer and consumer.
// - Last written value by the producer is never lost
// - Other conditions that relacy checks automatically:
// data races, deadlocks, livelocks.
struct TrioTest : rl::test_suite<TrioTest, kThreads> {
static constexpr size_t kLastNumber = 25;
bs::Trio<rl::var<int>> trio{};
void thread(unsigned thread_index) {
if (thread_index == 0) { // Producer
// Writing 25 integers
for (int i = 1; i <= kLastNumber; ++i) {
auto rlval = trio.Write()($);
rlval.store(i);
trio.Commit();
}
} else { // Consumer
// Read until we get 25. If 25 is never read
// relacy will report livelock.
int prev_read = 0;
while (prev_read != kLastNumber) {
auto& rlval = trio.Read();
int val = rlval($);
// Check order: new value must be >= than the previous
// It will be > when it's new value, and will
// be == to previous when we read stale data.
RL_ASSERT(val >= prev_read);
prev_read = val;
}
}
}
};
int main() {
rl::simulate<TrioTest>();
return 0;
}
Let’s compile and run it:
brilliantsugar $ clang++ test_relacy.cc -o ./test_relacy -g -O3 -I./ -I/relacy -std=c++20
brilliantsugar $ ./test_relacy
TrioTest
USER ASSERT FAILED (assertion: val >= prev_read)
iteration: 1
execution history (188):
[0] 1: [CTOR BEGIN], in fiber_proc_impl, ./../tests/relacy/relacy/context.hpp(457)
... skipped ...
[166] 0: <0x7fe2bef045b0> store, value=23, in thread, test_relacy.cc(23)
[167] 0: <0x7fe2bef04690> exchange , prev=0x7fe2bef045f0, arg=0x7fe2bef045b0, new=0x7fe2bef045b0, order=acq_rel, in Commit, ./trio.bug.relacy.h(27)
[168] 1: <0x7fe2bef04670> atomic load, value=0 [NOT CURRENT], order=relaxed, in Read, ./trio.bug.relacy.h(11)
[169] 1: <0x7fe2bef04630> load, value=20, in thread, test_relacy.cc(33)
[170] 0: <0x7fe2bef04670> atomic store, value=1, (prev value=1), order=relaxed, in Commit, ./trio.bug.relacy.h(29)
[171] 0: <0x7fe2bef045f0> store, value=24, in thread, test_relacy.cc(23)
[172] 1: <0x7fe2bef04670> atomic load, value=1 [NOT CURRENT], order=relaxed, in Read, ./trio.bug.relacy.h(11)
[173] 0: <0x7fe2bef04690> exchange , prev=0x7fe2bef045b0, arg=0x7fe2bef045f0, new=0x7fe2bef045f0, order=acq_rel, in Commit, ./trio.bug.relacy.h(27)
[174] 1: <0x7fe2bef04690> exchange , prev=0x7fe2bef045f0, arg=0x7fe2bef04630, new=0x7fe2bef04630, order=acq_rel, in Read, ./trio.bug.relacy.h(16)
[175] 1: <0x7fe2bef04670> atomic store, value=0, (prev value=1), order=relaxed, in Read, ./trio.bug.relacy.h(18)
[176] 1: <0x7fe2bef045f0> load, value=24, in thread, test_relacy.cc(33)
[177] 1: <0x7fe2bef04670> atomic load, value=0, order=relaxed, in Read, ./trio.bug.relacy.h(11)
[178] 1: <0x7fe2bef045f0> load, value=24, in thread, test_relacy.cc(33)
[179] 0: <0x7fe2bef04670> atomic store, value=1, (prev value=0), order=relaxed, in Commit, ./trio.bug.relacy.h(29)
[180] 0: <0x7fe2bef045b0> store, value=25, in thread, test_relacy.cc(23)
[181] 1: <0x7fe2bef04670> atomic load, value=0 [NOT CURRENT], order=relaxed, in Read, ./trio.bug.relacy.h(11)
[182] 1: <0x7fe2bef045f0> load, value=24, in thread, test_relacy.cc(33)
[183] 1: <0x7fe2bef04670> atomic load, value=1, order=relaxed, in Read, ./trio.bug.relacy.h(11)
[184] 1: <0x7fe2bef04690> exchange , prev=0x7fe2bef04630, arg=0x7fe2bef045f0, new=0x7fe2bef045f0, order=acq_rel, in Read, ./trio.bug.relacy.h(16)
[185] 1: <0x7fe2bef04670> atomic store, value=0, (prev value=1), order=relaxed, in Read, ./trio.bug.relacy.h(18)
[186] 1: <0x7fe2bef04630> load, value=20, in thread, test_relacy.cc(33)
[187] 1: USER ASSERT FAILED (assertion: val >= prev_read), in thread, test_relacy.cc(37)
Whoa, USER ASSERT FAILED (assertion: val >= prev_read)! Assert that all changes are propagated from consumer to producer in order have failed! Along with that Relacy printed a sequence of memory accesses that led my triple buffer to end up in this state.
We are only interested in a few last lines here. That’s where the problem is. Let’s illustrate what happened with a sequence diagram.
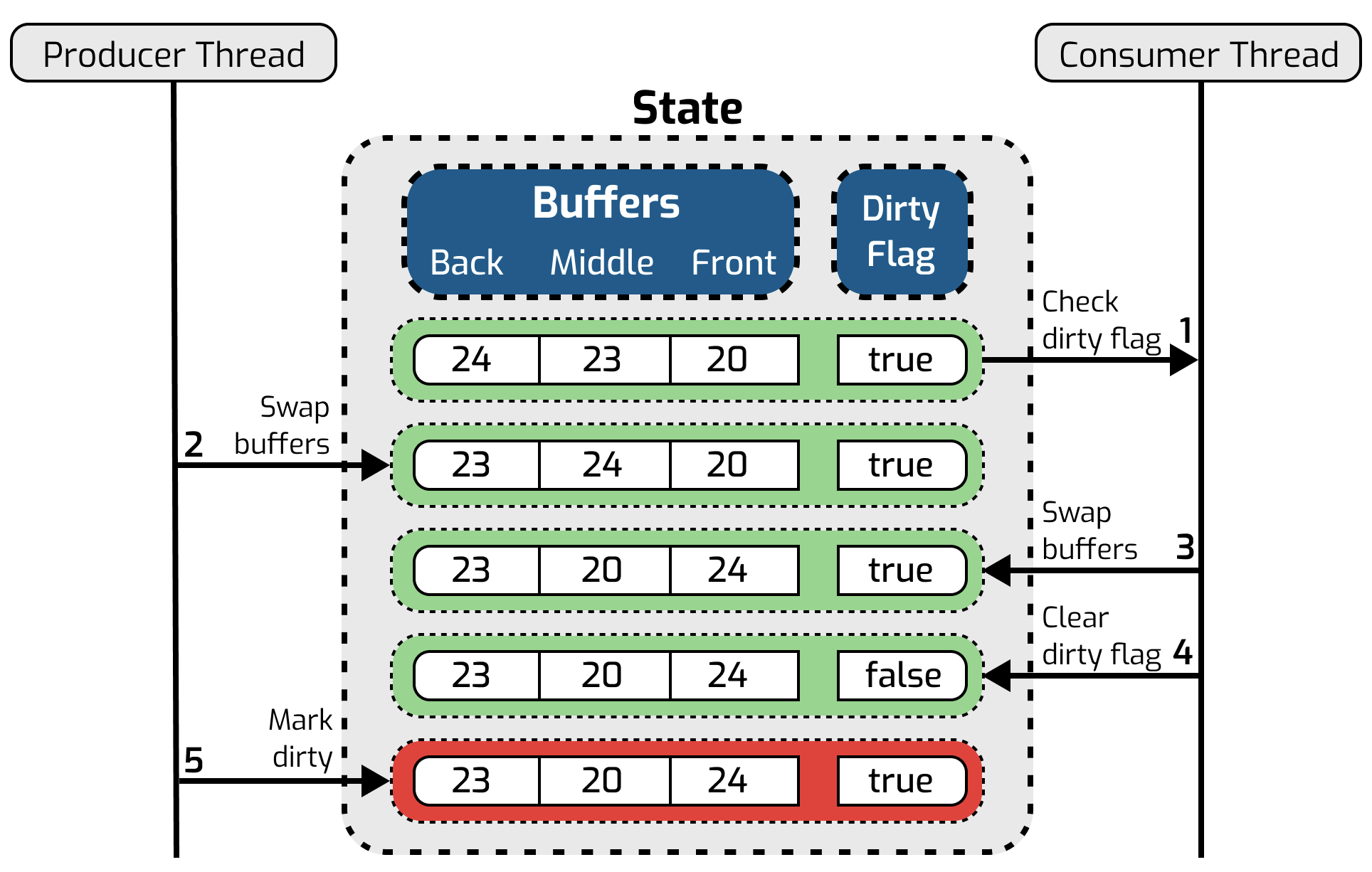 When the consumer’s and producer’s calls get interleaved as shown above - the consumer still sees a dirty flag from the previous write yet it is actually consuming new data. Then the producer marks data dirty again while our intermediate middle buffer contains garbage from the previous read. It’s clear to see that the next read will end up reading that stale data from the middle buffer and the system ends up in the wrong state.
We were able to derive the initial state of buffers from Relacy execution history and then it’s easy to notice a sequence of events that led the system into this state:
When the consumer’s and producer’s calls get interleaved as shown above - the consumer still sees a dirty flag from the previous write yet it is actually consuming new data. Then the producer marks data dirty again while our intermediate middle buffer contains garbage from the previous read. It’s clear to see that the next read will end up reading that stale data from the middle buffer and the system ends up in the wrong state.
We were able to derive the initial state of buffers from Relacy execution history and then it’s easy to notice a sequence of events that led the system into this state:
- [172] 1: <0x7fe2bef04670> atomic load, value=1 [NOT CURRENT], order=relaxed, in Read, ./trio.bug.relacy.h(11)
- [173] 0: <0x7fe2bef04690> exchange , prev=0x7fe2bef045b0, arg=0x7fe2bef045f0, new=0x7fe2bef045f0, order=acq_rel, in Commit, ./trio.bug.relacy.h(27)
- [174] 1: <0x7fe2bef04690> exchange , prev=0x7fe2bef045f0, arg=0x7fe2bef04630, new=0x7fe2bef04630, order=acq_rel, in Read, ./trio.bug.relacy.h(16)
- [175] 1: <0x7fe2bef04670> atomic store, value=0, (prev value=1), order=relaxed, in Read, ./trio.bug.relacy.h(18)
- [179] 0: <0x7fe2bef04670> atomic store, value=1, (prev value=0), order=relaxed, in Commit, ./trio.bug.relacy.h(29)
Our data race bug indeed did not get away from the relentless scrutiny of Relacy’s all-seeing eye. Now let’s correct it.
Corrected code
The core problem with our triple buffer is that dirty flag and buffer swapping are happening independently which gives an opportunity for those operations to be interleaved in a bad way. Can we tie them together so that swapping and dirtying data is done atomically?
The simplest way is to store the dirty flag along with the buffer pointers that we swap. The swap is done atomically so a dirty flag will get propagated from consumer to producer along with a swap.
Our buffers are already aligned to cache line size (64 on most common CPUs, 128 on some of Apple silicon) so that we can avoid the false sharing problem. That means that at least 6 of the least significant bits in every pointer will always be zeros. Knowing that, we can use the least significant bit to store the dirty flag:
template<typename T>
class Trio {
public:
Trio() = default;
T& Read() {
uintptr_t dirty_ptr = middle_buffer_.load(std::memory_order_relaxed);
if ((dirty_ptr & kDirtyBit) == 1) {
uintptr_t prev = middle_buffer_.exchange(reinterpret_cast<uintptr_t>(front_buffer_), std::memory_order_acq_rel);
front_buffer_ = reinterpret_cast<T*>(prev & kDirtyBitMask);
}
return *front_buffer_;
}
T& Write() {
return *back_buffer_;
}
void Commit() {
const uintptr_t dirty_ptr = kDirtyBit | reinterpret_cast<uintptr_t>(back_buffer_);
uintptr_t prev = middle_buffer_.exchange(dirty_ptr, std::memory_order_acq_rel) & kDirtyBitMask;
back_buffer_ = reinterpret_cast<T*>(prev);
}
private:
static constexpr size_t kNoSharing = 64;
static constexpr uintptr_t kDirtyBit = 1;
static constexpr uintptr_t kDirtyBitMask = ~uintptr_t() ^ kDirtyBit;
struct alignas(kNoSharing) Buffer {
T data{};
};
Buffer buffers_[3];
std::atomic<uintptr_t> middle_buffer_{reinterpret_cast<uintptr_t>(&buffers_[1].data)};
alignas(kNoSharing)
T* back_buffer_{&buffers_[0].data};
alignas(kNoSharing)
T* front_buffer_{&buffers_[2].data};
};
It is easy to get an instrumented code from this. Now let’s try to run it again:
brilliantsugar $ ./out/test_relacy
TrioTest
iterations: 1000
total time: 20
throughput: 50000
Our once-troubled triple buffer stands tall!
C11Tester
C11Tester is a research project from the University of California, Irvine. The core principle of C11Tester is the same as Relacy: it is trying to simulate all the possible states that your program might end up with given the C++ memory model. It uses a different graph traversal algorithm for finding which states are possible and emulating the visibility of store operations. There are more details on the exact algorithm in this paper. The authors claim that the algorithm allows much better performance compared to similar fuzzers and covers for larger variety of possible edge cases.
Another interesting thing is that, unlike Relacy, C11Tester does not require any special instrumentation of your code. Instead, the instrumentation is done at the compiler level. C11Tester utilizes clang plugins to instrument your code automatically. This also means it only works under Clang.
Finally, I got it running and printing out reasonable results. I only managed to get it working under Clang 8 which is quite a bummer. (The current Clang version at the time of this article is 17)Navigating the treacherous waters of C11Tester was a twisted expedition that swallowed chunks of time. The instructions that accompanied this enigmatic creature were incomplete, pushing me to embark on a quest through the C11Tester code.
Let’s try C11Tester on our buggy triple-buffer:
#include <trio.h>
#include <model-assert.h>
#include <thread>
namespace {
static constexpr size_t kLastNumber = 25;
bs::Trio<int> trio{};
}
// Write ints from 1 to 25 into the triple buffer
void producer() {
for (int i = 1; i <= kLastNumber; ++i) {
trio.Write() = i;
trio.Commit();
}
}
int main() {
auto producer_thread = std::thread(producer);
int prev_read = 0;
while (prev_read != kLastNumber) { // Read ints from the buffer
const auto& val = trio.Read();
MODEL_ASSERT(val >= prev_read); // Check numbers come in the expected order
prev_read = val;
}
producer_thread.join(); // Hang forever if we never get the last number
return 0;
}
Let’s compile this with C11Tester hooked up and run it.
brilliantsugar $ LD_LIBRARY_PATH=c11tester clang++-8 -Xclang -load -Xclang llvm-8.0.1.src/build/lib/libCDSPass.so -Lc11tester/ -lmodel -Ic11tester/include -g -O3 -rdynamic test_c11tester.cc -o out/test_c11tester
brilliantsugar $ ./out/test_c11tester
C11Tester
Copyright (c) 2013 and 2019 Regents of the University of California. All rights reserved.
Distributed under the GPLv2
Written by Weiyu Luo, Brian Norris, and Brian Demsky
Program output from execution 1:
---- BEGIN PROGRAM OUTPUT ----
---- END PROGRAM OUTPUT ----
Number of complete, bug-free executions: 0
Number of buggy executions: 1
Total executions: 1
Bug report: 1 bug detected
[BUG] Program has hit assertion in file test_c11tester.cc at line 25
Execution trace 1: DETECTED BUG(S)
------------------------------------------------------------------------------------
# t Action type MO Location Value Rf CV
------------------------------------------------------------------------------------
1 1 thread start seq_cst 00007FB936A9A0D0 0xdeadbeef ( 0, 1)
2 1 pthread create seq_cst 00007FFEF8C13608 0x7ffef8c135b0 ( 0, 2)
3 2 thread start seq_cst 00007FB93821BA18 0xdeadbeef ( 0, 2, 3)
4 1 atomic read relaxed 00000000006031C0 0 0 ( 0, 4)
5 1 atomic read relaxed 00000000006031C0 0 0 ( 0, 5)
6 2 atomic rmw acq_rel 00000000006031C8 0x603140 (603180) 0 ( 0, 2, 6)
7 2 atomic write relaxed 00000000006031C0 0x1 ( 0, 2, 7)
8 1 atomic read relaxed 00000000006031C0 0 0 ( 0, 8)
9 1 atomic read relaxed 00000000006031C0 0 0 ( 0, 9)
10 2 atomic rmw acq_rel 00000000006031C8 0x603180 (603140) 6 ( 0, 2, 10)
11 2 atomic write relaxed 00000000006031C0 0x1 ( 0, 2, 11)
12 1 atomic read relaxed 00000000006031C0 0x1 7 ( 0, 12)
13 2 atomic rmw acq_rel 00000000006031C8 0x603140 (603180) 10 ( 0, 2, 13)
14 2 atomic write relaxed 00000000006031C0 0x1 ( 0, 2, 14)
15 1 atomic rmw acq_rel 00000000006031C8 0x603180 (603100) 13 ( 0, 15, 13)
16 1 atomic write relaxed 00000000006031C0 0 ( 0, 16, 13)
17 1 atomic read relaxed 00000000006031C0 0x1 14 ( 0, 17, 13)
18 1 atomic rmw acq_rel 00000000006031C8 0x603100 (603180) 15 ( 0, 18, 13)
19 1 atomic write relaxed 00000000006031C0 0 ( 0, 19, 13)
HASH 280478415
------------------------------------------------------------------------------------
******* Model-checking complete: *******
Number of complete, bug-free executions: 0
Number of buggy executions: 1
Total executions: 1
C11Tester had no issues finding the same race as Relacy. It does seem like it required a bit less steps to find it. Compared to Relacy - It’s a bit harder to follow the output because to understand the order of actual reads and writes on each thread you need to follow vector clocks sequence numbers (CV column on the right). Additionally, it doesn’t track the state of non-atomic variables - making it harder to understand what state your program was in when assert hit.
Overall, C11Tester looks very promising but requires quite a bit of work to turn it from a research project into an everyday tool (A port to more recent LLVM/Clang versions would be great).
Spin
Moving on to a more exotic tool. Spin is a formal verification tool. For those unfamiliar, the way the formal verification usually works: you define a mathematical model of your algorithm via some intermediate language and then you can run a variety of tests on that model. That includes tests that the system invariants hold and tests for deadlocks and livelocks.
The hardest part of a formal verification system is to correctly model the program in question. Spin is using the language Promela to define a model. Compared to other similar toolkits (i.e. TLA+, Coq) Promela has a more humane syntax that doesn’t shock a typical programmer as much.
Another problem is that Promela doesn’t know anything about CPUs or C++ memory model. That means you need to first model your CPU architecture and C++ memory model in Promela. That turned out an extremely non-trivial task that people dedicate their Ph.D. theses.
An expedition through a maze of websites and papers, a bizarre assortment and some Google-translated from the Japanese, I stumbled upon a peculiar project called MMLIB.
mmlib provides a Promela model that emulates the Total Store Ordering (TSO) and the Partial Store Ordering (PSO) memory models. Those models are formalized mathematical definitions of common CPU memory models, e.g. the TSO model essentially emulates memory access ordering guarantees that are akin to x86 CPUs.
Let’s try to write Promela code to simulate our original buggy triple buffer implementation:
// Setup mmlib
#define PROCSIZE 2 // number of threads
#define VARSIZE 7 // number of variables
#define BUFFSIZE 16 // max queue size for reads
#include "mmlib/library/tso.h" // use TSO model, and apply above defines
// Variables indices
#define front_buffer_ptr 0
#define back_buffer_ptr 1
#define middle_buffer_ptr 2
#define buffer0 3
#define buffer1 4
#define buffer2 5
#define dirty 6
#define max_number 25
// Atomic swap (emulates std::atomic_exchange)
inline ATOMIC_EXCHANGE(obj, desired) {
atomic {
prev = READ(obj);
WRITE(obj, desired);
FENCE();
}
}
inline SWAP_BUFFERS(middle_buffer, other_buffer) {
int prev;
int other_buffer_ptr = READ(other_buffer);
ATOMIC_EXCHANGE(middle_buffer, other_buffer_ptr);
WRITE(other_buffer, prev);
}
proctype Producer() {
int value = 0;
do
:: value > max_number -> break
:: else ->
value = value + 1;
int write_buffer = READ(back_buffer_ptr);
// Dispatch those writes into labels so that
// we can easily verify the mutual exclusivity of reads and writes
// in the never{} clause.
if
:: write_buffer == buffer0 -> goto write0;
:: write_buffer == buffer1 -> goto write1;
:: write_buffer == buffer2 -> goto write2;
fi;
write0:
WRITE(buffer0, value); goto commit;
write1:
WRITE(buffer1, value); goto commit;
write2:
WRITE(buffer2, value); goto commit;
commit:
SWAP_BUFFERS(middle_buffer_ptr, back_buffer_ptr);
WRITE(dirty, 1);
od;
}
proctype Consumer() {
int value = 0, prev_value = 0;
do
:: value == max_number -> break
:: else ->
if
:: READ(dirty) == 1 ->
SWAP_BUFFERS(middle_buffer_ptr, front_buffer_ptr);
WRITE(dirty, 0);
:: else
fi;
int read_buffer = READ(front_buffer_ptr);
if
:: read_buffer == buffer0 -> goto read0;
:: read_buffer == buffer1 -> goto read1;
:: read_buffer == buffer2 -> goto read2;
fi;
read0:
value = READ(buffer0); goto check_order;
read1:
value = READ(buffer1); goto check_order;
read2:
value = READ(buffer2); goto check_order;
check_order:
assert(value >= prev_value);
prev_value = value;
od;
}
// Setup producer and consumer and shared buffers
init {
INIT(front_buffer_ptr, buffer0);
INIT(back_buffer_ptr, buffer1);
INIT(middle_buffer_ptr, buffer2);
INIT(buffer0, 0);
INIT(dirty, 0);
atomic {
run Producer();
run Consumer();
}
}
// Check system-wide invariants that we expect to always hold
never {
T0_init:
do
// We expect producer and consumer to never write and read from the same buffer concurrently
:: atomic { (Producer@write0 && Consumer@read0) -> assert(!(Producer@write0 && Consumer@read0)) }
:: atomic { (Producer@write1 && Consumer@read1) -> assert(!(Producer@write1 && Consumer@read1)) }
:: atomic { (Producer@write2 && Consumer@read2) -> assert(!(Producer@write2 && Consumer@read2)) }
:: (1) -> goto T0_init
od;
accept_all:
skip;
}
As expected, running Spin revealed the same bug as Relacy and C11Tester:
brilliantsugar $ spin -run -t trio.bug.pml
pan:1: assertion violated (value>=prev_value) (at depth 3383)
pan: wrote trio.bug.pml.trail
... skipped ...
As well as other tools, Spin provides a trace of states that led to the assertion:
brilliantsugar $ spin -t -p trio.bug.pml
...skipped...
378: proc 3 (Consumer:1) trio.bug.pml:76 (state 56) [read_buffer = ( ((counter[((_pid*7)+0)]==0)) -> (shared_memory[0]) : (buffer[((_pid*7)+0)]) )]
3380: proc 3 (Consumer:1) trio.bug.pml:79 (state 61) [((read_buffer==5))]
3382: proc 3 (Consumer:1) trio.bug.pml:86 (state 69) [value = ( ((counter[((_pid*7)+5)]==0)) -> (shared_memory[5]) : (buffer[((_pid*7)+5)]) )]
spin: trio.bug.pml:88, Error: assertion violated
Having explored Relacy, C11Tester, and Spin for testing my lock-free C++ code, I ultimately settled upon Relacy as my tool of choice. The instrumentation required for Relacy is trivial, the output it provides is clean and easy to follow. It works with all major compilers effortlessly despite its age. C11Tester seems good but requires too much work to get it into a usable shape. Spin and other formal verification tools require modeling CPU memory access ordering in exotic languages. Then you need to model your own data structures. During the process of modeling and translating the model to C++, another juncture emerges where bugs may subtly slip into the code.
All code is available here